物理运动经常可以用二阶常微分方程表示,以单摆运动为例:
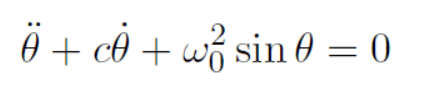
求解物体运动的过程,可以转化为二阶常微分方程的数值解问题。那么如何求解二分常微分方程呢?最主要的思想就是把微分方程的自变量离散化,分成很多份,如果每份足够小,那么可以认为这一份上的增长率是相同的,即可以近似的认为
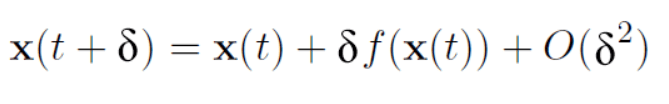
舍去高阶项便得到Euler方法,既如下递推关系:
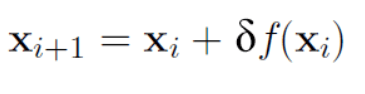
用C#可以很简单的实现:
/// 欧拉方法,用步进的方式求一阶常微分方程
/// y_present : 时间片内函数的初始值
/// z_present : 函数的一阶导数
/// dt : 时间片的长度
/// return : 下一个时间片函数的初始值
float Y_NEXT(float y_present, float z_present, float dt)
{
return y_present + dt * z_present;
}
上述代码可以直接用于一阶常微分方程的求解,但是对于二阶常微分方程,函数本身随其一阶导数变化,其一阶导数随自变量变化,所以对一阶导数和函数都需要计算:
/// 使用欧拉方法求平面摆运动
/// present : 平面摆在时间片内的初始状态
/// dt : 时间片长度
/// z_d : 二阶常微分方程
/// return : 下一个时间片平面摆的初始状态
Vector2 Euler(Vector2 present, float dt, Func z_d)
{
float y_present = present.x, z_present = present.y;
float y_next = Y_NEXT(present.x, present.y, dt);
float z_next = Y_NEXT(z_present, z_d(y_present, z_present), dt);
return new Vector2(y_next, z_next);
}
由于欧拉方法没有对时间段内的增长率做任何优化,所以误差比较大。于是有了改进的欧拉方法,主要思想是在时间片内取首尾的两个位置,然后取它们的平均增长率。首位就是我们的初始状态,末位就是根据初始状态,用欧拉方法求得的下一个状态。
/// 改进的欧拉算法
Vector2 ImprovedPendulumDynamics(Vector2 present, float dt, Func z_d)
{
/*
实现公式
y[k+1] = y[k] + 1/2 * (k1+k2)
z[k+1] = z[k] + 1/2 * (l1+l2)
k1 = z[k], l1 = f(x[k],y[k],z[k])
k2 = z[k]+h*l1, l2 = f(x[k]+h, y[k]+h*k1, z[k]+h*l1)
也写成 l2 = f(x[k]+h, y[k]+h*k1, k2)
k表示一阶导数,l表示二阶导数,h表示时间片长度
k1、k2分别表示两个不同的状态处的一阶导数
函数f(x,y,z) 即为二阶常微分方程,既函数Z_D(y[k],z[k])
运算y[k] + h*k1,即为欧拉方法求一阶常微分方程的过程Y_NEXT(y[k],k1,dt)
*/
float y_present = present.x, z_present = present.y;
float k1 = z_present;
float l1 = z_d(y_present, z_present);
float k2 = Y_NEXT(z_present, l1, dt);
float y_l2 = Y_NEXT(y_present, k1, dt);
float l2 = z_d(y_l2, k2);
float z_fixed = (k1 + k2) / 2;
float zd_fixed = (l1 + l2) / 2;
float y_next = Y_NEXT(y_present, z_fixed, dt);
float z_next = Y_NEXT(z_present, zd_fixed, dt);
return new Vector2(y_next, z_next);
}
这个时候的增长率比起欧拉方法来说,已经改进了。那么如果我们用已经改进过的增长率,取更多的点来用同样的形式持续的改进增长率呢?我们会得到精度更高的解。这就是龙格库塔算法的思想,下面是一个4阶龙格库塔的实现:
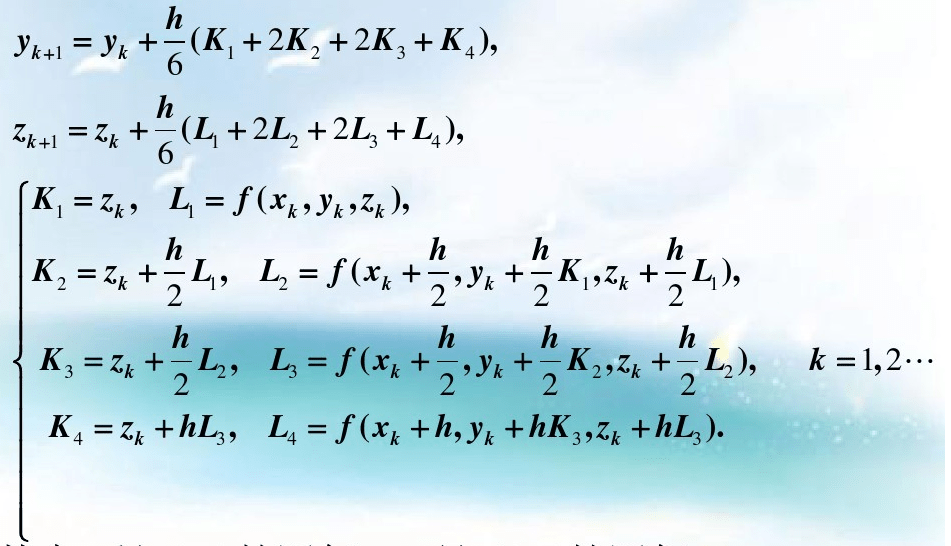
/// Fourth-Order Runge-Kutta method
Vector2 RK4(Vector2 present, float dt, Func z_d)
{
float y_present = present.x, z_present = present.y;
float k1 = z_present;
float l1 = z_d(y_present, z_present);
float k2 = Y_NEXT(z_present, l1, dt / 2);
float y_l2 = Y_NEXT(y_present, k1, dt / 2);
float l2 = z_d(y_l2, k2);
float k3 = Y_NEXT(z_present, l2, dt / 2);
float y_l3 = Y_NEXT(y_present, k2, dt / 2);
float l3 = z_d(y_l3, k3);
float k4 = Y_NEXT(z_present, l3, dt);
float y_l4 = Y_NEXT(y_present, k3, dt);
float l4 = z_d(y_l4, k4);
float z_fixed = (k1 + 2 * k2 + 2 * k3 + k4) / 6;
float zd_fixed = (l1 + 2 * l2 + 2 * l3 + l4) / 6;
float y_next = Y_NEXT(y_present, z_fixed, dt);
float z_next = Y_NEXT(z_present, zd_fixed, dt);
return new Vector2(y_next, z_next);
}
我们可以看到,龙格库塔是通过迭代持续改进增长率的。
最后,在把数学式转化为代码的时候,最好让函数的参数和数学式保持一致,这样在迭代的时候思路会更加顺畅。
